 Akadēmiskais centrs
Akadēmiskais centrs
PROJEKTS
Parakstīts līgums ar Centrālo finanšu un līguma aģentūru (CFLA) darbības programmas “Izaugsme un nodarbinātība” 1.1.1.specifiskā atbalsta mērķa “Palielināt Latvijas zinātnisko institūciju pētniecisko un inovatīvo kapacitāti un spēju piesaistīt ārējo finansējumu, ieguldot cilvēkresursos un infrastruktūrā” 1.1.1.1. pasākuma “Praktiskas ievirzes pētījumi” ietvarā, par projekta:
“Daudzvalodu cilvēka-datora komunikācijas modelēšana, izmantojot mākslīgā intelekta metodes” (1.1.1.1/18/A/148) īstenošanu.
Projekts tiks īstenots sadarbībā starp - Sabiedrību Tilde un pētniecības institūciju - Latvijas Universitātes Datorikas fakultāti.
Projekts ilgs no 2019. gada 1. aprīļa līdz 2022. gada 31. martam.
Projekta kopējas attiecināmās izmaksas ir 756 694.09 EUR, t.sk., ERAF atbalsts 519 332.49 EUR.
Projekta īstenošanas vieta – Vienības gatve 75a, Rīga, Latvija un Raiņa bulvāris 19, Rīga, Latvija, LV-1586.

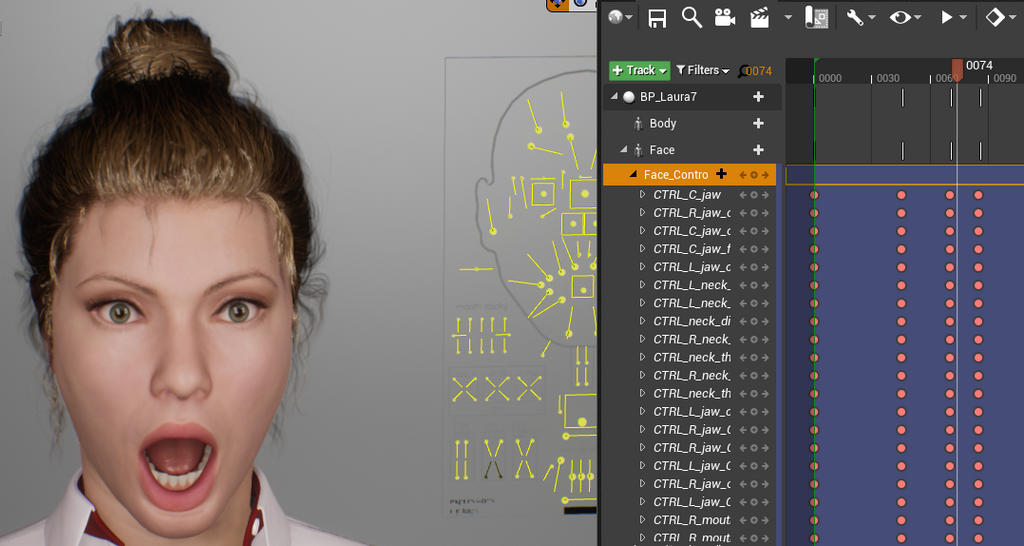
Pārskata posms: 04.04.2021-28.06.2022
Projekta īstenošanas 13. posmā ir pabeigta gala mākslīgā intelekta metodēs balstīta multilingvāla un multimodāla virtuālā aģenta prototipa izveide. Prototipā integrēti labākie pētniecības aktivitātēs radītie komponenti. Prototipa veidošanai izmantots Unreal Engine 4 (UE4) izstrādes rīks. Prototips nodrošina lietotāja dialogu ar botu latviešu valodā (tekstuāli un audiāli (aktivitāte 5)) un angļu valodā (tekstuāli). Bota zināšanas ir modelētas angļu valodā (aktivitāte 1), daudzvalodīga saziņa tiek nodrošināta ar mašīntulkošanas komponentes (aktivitāte 3) palīdzību. Prototipā iekļauts arī emociju noteikšanas modulis (aktivitāte 4), kas ļauj sagatavot atbildi atbilstoši lietotāja noskaņojumam. Sagatavots novērtējuma ziņojums, prototips publicēts GitHub repozitorijā: https://github.com/tilde-nlp/pip2-final-prototype.
Publicēts: 29.06.2022

Pārskata posms: 01.12.2021 - 25.03.2022
Projekta īstenošanas 12. posmā tika turpināta galīgā mākslīgā intelekta metodēs balstīta multilingvāla un multimodāla virtuālā aģenta prototipa izveide, integrējot tajā jaunākos pētniecības aktivitāšu rezultātus. Vairākās iterācijā notika gala prototipa darbplūsmu modelēšana, tika veikta atsevišķo pētniecības aktivitāšu moduļu savstarpējās mijiedarbības un sadarbspējas novērtēšana dažādos scenārijos. Vienlaikus tika strādāts pie risinājuma, lai modelētu virtuālā aģenta izpratni par lietotāja emocionālo stāvokli.
Publicēts: 25.03.2022
Projekta īstenošanas 11. posmā pabeigti pētījumi par dabiskās valodas sapratnes modelēšanu, zināšanu izguvi no daudzvalodu tekstiem, daudzvalodīgas piekļuves nodrošināšanu, cilvēka-datora saziņas emocionālajiem aspektiem un runātās valodas paralingvistisko parametru modelēšanu. Pētījumu rezultāti apkopoti nodevumos, publikācijās, datu kopās un prototipos. Tie prezentēti RANLP 2021 un Future Technologies konferencēs.
Pabeigts prototips vairākvārdu savienojumu un vārdkopu ģenerēšanai, kas ietver teksta dalīšanu tekstvienībās, to morfoloģisko analīzi un sintaktisko parsēšanu, morfoloģisko īpašību piešķiršanu sintakses kokiem un morfoloģisko sintēzi.
Pabeigts pētījums par daudzvalodīgas piekļuves nodrošināšanu ar mašīntulkošanas risinājumu starpniecību virtuālajiem asistentiem, kas nodrošina saziņu angļu valodā. Pabeigts darbs pie laboratoriskā prototipa, kas demonstrē starpvalodu zināšanu pārnesi, izmantojot mašīntulkošanas tehnoloģijas un angļu valodas tērzēšanas bota/jautājumu-atbilžu sistēmu.
Lietotāja emocionālā stāvokļa modelēšanas uzdevumā pabeigta dialoga emociju intensitātes prognozēšanas modeļa izstrāde, veikta datu apstrāde dialoga emociju intensitātes izmaiņu modelēšanā klientu atbalsta tvītiem, aprakstīšana un prezentēšana.
Līdz ar pētījuma aktivitāšu pabeigšanu intensificēta gala mākslīgā intelekta metodēs balstīta multilingvāla un multimodāla virtuālā aģenta prototipa izveide, analizēta jaunāko pētniecības aktivitāšu rezultātu iekļaušana prototipā, to savietojamība un tehnoloģiskā gatavība.
Publicēts 16.12.2021.
Projekta īstenošanas 10. posmā turpināti pētījumi par dabiskās valodas sapratnes modelēšanu, zināšanu izguvi no daudzvalodu tekstiem, daudzvalodīgas piekļuves nodrošināšanu, cilvēka-datora saziņas emocionālajiem aspektiem un runātās valodas paralingvistisko parametru modelēšanu. Pabeigts pētījums par paralingvistisko pazīmju atpazīšanu un runātās valodas apstrādi dialogos. Turpinās gala mākslīgā intelekta metodēs balstīta multilingvāla un multimodāla virtuālā aģenta prototipa izveide.
Dabiskās valodas ģenerēšanas uzdevumā turpināta frāžu ģenerēšanas prototipa izveide. Pabeigti eksperimenti ar dažādu teikumu vektortelpu noteikšanas modeļu iekļaušanu nākamās darbības prognozēšanas modelī.
Pabeigti pētījumi par zināšanu identificēšanu tekstā un metodēm multilingvālai zināšanu izguvei no datubāzēm.
Turpināts darbs pie mašīntulkošanas tehnoloģiju lietojamības izpētes saziņas nodrošināšanai ar angļu valodas tērzēšanas bota/jautājumu-atbilžu sistēmas platformu, izmantojot mašīntulkošanas tehnoloģijas un angļu valodas tērzēšanas bota/jautājumu-atbilžu sistēmu. Pētīta saziņa ar Amazon Lex platformā izveidotajiem virtuālajiem asistentiem.
Lietotāja emocionālā stāvokļa noteikšanas uzdevumā veikta kvantitatīvā aptauja, ievācot datus uzņēmu klientu vidū, kas izmanto ikdienas darbā sarunbotus. Turpināts darbs pie afektīvo pazīmju kataloga pirmās versijas. Turpināts veidot latviešu valodas vārdu katalogu, kurā katra vienība marķēta ar valences un aktivizācijas rādītājiem.
Sekmīgi pabeigts pētījums par paralingvistisko īpatnību atpazīšanu un sintēzi runā. Pētījuma rezultāti apkopoti nodevumā, publikācijās, datu kopā un prototipos.
Publicēts 19.08.2021.
Projekta īstenošanas 9. posmā turpināti pētījumi par dabiskās valodas sapratnes modelēšanu, zināšanu izguvi no daudzvalodu tekstiem, daudzvalodīgas piekļuves nodrošināšanu, cilvēka-datora saziņas emocionālajiem aspektiem un runātās valodas paralingvistisko parametru modelēšanu. Pabeigts pētījums par paralingvistisko pazīmju atpazīšanu un runātās valodas apstrādi dialogos. Turpinās gala mākslīgā intelekta metodēs balstīta multilingvāla un multimodāla virtuālā aģenta prototipa izveide.
Dabīgās valodas sapratnes modelēšanas uzdevumā turpināti iepriekšējā atskaites periodā uzsāktie eksperimenti ar dažādu teikumu vektortelpu noteikšanas modeļu iekļaušanu nākamās darbības prognozēšanas modelī, analizējot LaBSE (Feng.F et.al., 2020) un paraphrase-xlm-r-multilingual-v1 (Reimers & Gurevych, 2020) modeļu lietojamību. Eksperimenti parādīja, ka apmierinošus rezultātus iespējams sasniegt, apmācot modeļus ar dialogu kopu vairākās valodās vai apmācot vienā valodā un izmantojot citā valodā. Šo pieeju var izmantot gadījumos, kad apmācības dati kādā valodā nav pietiekami, ja vien vektortelpu modelis ir piemērots abām valodām.
Dabiskās valodas ģenerēšanas uzdevumā, apvienojot vairākus valodas apstrādes rīkus, ir izveidots frāžu locītājs, kurš spēj ģenerēt frāzes (vairākvārdu savienojumus) dažādos locījumos. Frāžu locītāja darbplūsma ietver teksta dalīšanu tekstvienībās, katras tekstvienības morfoloģisku analīzi, sintaktisko parsēšanu, morfoloģisko īpašību piešķiršanu sintakses kokiem saskaņā ar sintakses likumiem un morfoloģisko sintēzi. Izmantojot frāžu locītāju, ir izveidota datu kopa, kas satur atvērto datu portālā publicēto publisko personu un iestāžu nosaukumus locījuma formās.
Turpināts analizēt jaunākos pētījumus par risinājumiem, kas ļauj veidot vaicājumus dabiskā valodā un tos automātiski pārveidot SQL vai kādā citā tehniskā vaicājumu valodā. Izstrādātas metodes un jauns risinājums, kas ar virtuālā asistenta palīdzību ļauj lietotājam izveidot vaicājumu zinību bāzei. Metožu izvērtēšanai izveidoti divi virtuālie asistenti: (1) ADQL vaicājumu veidošanai zināšanu izguvei no Gaia Archive zināšanu bāzes un (2) SQL vaicājumus zināšanu izguvei no Open Food Facts zināšanu bāzes. Veikta kvalitatīva Open Food Facts virtuālā asistenta analīze, iesaistot VA testēšanā 15 respondentus.
Turpināts darbs pie mašīntulkošanas tehnoloģiju lietojamības izpētes saziņas nodrošināšanai ar angļu valodas tērzēšanas bota/jautājumu-atbilžu sistēmas platformu, izmantojot mašīntulkošanas tehnoloģijas un angļu valodas tērzēšanas bota/jautājumu-atbilžu sistēmu.
Lietotāja emocionālā stāvokļa noteikšanas uzdevumā izveidots pirmais afekta pazīmju katalogs latviešu valodā. Katalogā apkopotas lingvistiskās un paralingvistiskās pazīmes, kas var liecināt par afekta pazīmēm lietotāju dialogu audiālajā daļā.
Paralingvistisko pazīmju atpazīšanas uzdevumā pabeigts pētīt emociju atpazīšanu audiodatos. Secināts, ka telefona zvanu ierakstu analīze ir izaicinošs uzdevums paralingvistisko pazīmju atpazīšanas modeļiem, kuru precizitāte tikai nedaudz pārsniedz 50%. Tomēr, tā pārspēj neapmācītu cilvēku, kura rezultāts pētījumā bija 22.72%.
Publicēts 16.06.2021.
Projekta īstenošanas 8. posmā turpināti pētījumi par dabiskās valodas sapratnes modelēšanu, zināšanu izguvi no daudzvalodu tekstiem, daudzvalodīgas piekļuves nodrošināšanu, cilvēka-datora saziņas emocionālajiem aspektiem un runātās valodas paralingvistisko parametru modelēšanu. Šajā posmā pabeigts pētījums par izteiksmīgas runas sintēzi dialogiem. Uzsākta galīgā mākslīgā intelekta metodēs balstīta multilingvāla un multimodāla virtuālā aģenta prototipa izveide.
Dabīgās valodas sapratnes modelēšanas uzdevumā turpināti iepriekšējā atskaites periodā uzsāktie eksperimenti ar dažādu teikumu vektortelpu noteikšanas modeļu iekļaušanu nākamās darbības prognozēšanas modelī, analizējot LaBSE (Feng.F et.al., 2020) un paraphrase-xlm-r-multilingual-v1 (Reimers & Gurevych, 2020) modeļu lietojamību. Modeļu darbība pārbaudīta, apmācot modeli ar vienas valodas datiem, bet novērtējot ar otras valodas datiem, kā arī apmācot ar abu valodu datiem. Vislabākie rezultāti iegūti ar LaBSE vektortelpu modeli, modeļa akurātumam sasniedzot 0,909.
Turpinot pētījumus par zināšanu izvilkšanu no daudzvalodu tekstiem un zināšanu bāzes izveidi, pētītas metodes nosaukto entitāšu atpazīšanai, izmantojot vienu modeli, kas apmācīts ar datiem vairākās valodās un spēj atpazīt entitātes vairākās valodās. Pilnveidota metode atrasto entitāšu piesaistei zināšanu bāzei. Metode izmanto entitāšu jēdzientelpas vektorus, kas atrastajai entitātei tiek salīdzināti ar kandidātu entitātēm zināšanu bāzē. Atbilstības noteikšanai tiek izmantots daudzvalodu LaBSE modelis, kurš ņem vērā kontekstu, kurā entitāte minēta. Metode uzrādīja labāko rezultātu daudzvalodu entitāšu sasaistes uzdevumā (Cross-lingual entity linking) BSNLP 2021 darbsemināra rīkotajās sacensībās "3rd Shared Task on SlavNER".
Uzsākts darbs pie mašīntulkošanas tehnoloģiju lietojamības izpētes saziņas nodrošināšanai ar angļu valodas tērzēšanas bota/jautājumu-atbilžu sistēmas platformu, izmantojot mašīntulkošanas tehnoloģijas un angļu valodas tērzēšanas bota/jautājumu-atbilžu sistēmu.
Lietotāja emocionālā stāvokļa noteikšanas uzdevumā izveidota aptauja, ar kuru iecerēts veikt kvantitatīvu pētījumu, izpētot cik un vai sarunbotu lietotājiem ir svarīgi, ka mākslīgā intelekta sistēma atpazīst afekta pazīmes un pielāgo dialogu. Savukārt lietotāja emocionālā stāvokļa modelēšanas uzdevumā veikti eksperimenti dialoga emociju intensitātes izmaiņu modelēšanā latviešu valodas dialogiem, kas iegūti no telekomunikāciju uzņēmumu atbalsta tvītiem. Tika izveidota metode emociju intensitātes modelēšanai, kas papildus izmanto arī neleksiskos līdzekļus (piemēram, ne-burtu simbolus, specifiska reģistra vārdus). Eksperimenta gaitā izdevās parādīt, ka, papildus izmantojot neleksiskos līdzekļus, iespējams labāk prognozēt emociju intensitāti.
Pabeigts pētījums par Izteiksmīgas runas sintēzi dialogiem. Pētījuma rezultātā kā labākā metode tika atzīta vairākrunātāju Tacotron 2 ar GST, kura svari inicializēti ar Mellotron GST svariem. Šī metode tika izmantota izteiksmīgas runas sintēzes prototipa izveidē. Prototips tika veidots kā sarunbotu pārvaldības sistēmas papildinājums, kas ļauj kontrolēt katru sarunbota atbildes izteiksmi, norādot stila marķējumu svērtās summas svarus. Lai noteiktu nepieciešamos svarus, tika izveidots papildu rīks, kas ļauj lietotājam veikt teksta sintēzi un norādīt katra marķiera svaru.
Publicēts 31.03.2021.
Projekta īstenošanas 7. posmā turpināti pētījumi par dabiskās valodas sapratnes modelēšanu, zināšanu izguvi no daudzvalodu tekstiem, daudzvalodīgas piekļuves nodrošināšanu, cilvēka-datora saziņas emocionālajiem aspektiem un runātās valodas paralingvistisko parametru modelēšanu. Pabeigta sākotnējā multilingvālā virtuālā aģenta prototipa izveide.
Dabīgās valodas sapratnes modelēšanas uzdevumā turpināti pētījumi par nodoma noteikšanu kļūdainos lietotāja izteikumos. Pētījumā turpināta kļūdaino datu priekšapstrādes un apmācības datu palielināšanas/samazināšanas ietekmes analīze nodoma noteikšanas uzdevumā. Secināts, ka metodes lielāku pienesumu dod scenārijos ar samazinātu apmācības datu apjomu, ļaujot palielināt nodoma noteikšanas precizitāti par 2%-4%. Savukārt dabiskās valodas sapratnes uzdevumā radītais personvārdu formu ģenerēšanas modelis paplašināts, nodrošinot vairākvārdu savienojumu (nosaukto entitāšu) formu ģenerēšanu.
Dialogu scenāriju mācīšanās no datiem uzdevumā turpināta metožu pilnveide nākamās darbības prognozēšanai, izmantojot neironu tīklu modeļu arhitektūru un apmācības datos iekļaujot ekstralingvistisku informāciju. Šajā uzdevumā novērtēti vairāki valodas modeļi – FastText, BERT un BERT-LV. Labākie rezultāti iegūti ar FastText, kur modeļa akurātums sasniedz 0,911.
Turpinot pētījumus par zināšanu identificēšanu un zināšanu bāzes izveidi, tika pētītas metodes, kas nosaukto entitāšu identificēšanas uzdevumā ir noturīgas pret kļūdām lietotāja izteikumos. Izveidots nosaukto entitāšu atpazīšanas modelis, kas spēj veiksmīgi atpazīt kļūdaini uzrakstītas entitātes. Strādājot ar šādiem kļūdainiem datiem, bāzlīnijas sistēmas veiktspēja samazinājās līdz pat 50 F1 punktiem. Savukārt pētījuma robustās sistēmas kļūdainam tekstam uzrāda tikai līdz 2 F1 punktu veiktspējas kritumu.
Lietotāja emocionālā stāvokļa noteikšanas uzdevumā, izmantojot kvalitatīvās pētniecības metodes, pabeigta detalizēta 40 dialogu (378,28 minūtes, 17 638 segmentus) anotēšana, izveidojot 11 sinhronus slāņus, kuros aprakstītas un anotētas lingvistiskas, paralingvistiskas vienības, kurām varētu būt afektīva nozīme. Datu kopa ļauj izstrādāt pirmo afektīvo pazīmju modeli telefonsarunu dialogiem, ko var izmantot turpmākiem kvantitatīviem pētījumiem un praktiskiem mērķiem, piemēram, runātāju afektīvo pazīmju noteikšanai attiecībā pret dialoga saturu. Papildus izveidots visu dialogu mērķu sasniegšanas novērtējums, kas kalpos par atskaites punktu afektīvo pazīmju dinamikas novērtēšanai.
Lietotāja emocionālā stāvokļa modelēšanas uzdevumā veikti pētījumi un izstrādāts modelis dialoga emociju intensitātes izmaiņu modelēšanai. Pētījumā tika modelēts nākamā soļa neapmierinātības līmenis pēc iepriekšējā lietotāja puses un tam sekojošā atbalsta dialoga gājiena teksta. Pētījuma gaitā, prognozējot nākamā soļa neapmierinātības līmeni, neizdevās parādīt atbalsta puses teksta pienesumu pret vienkārši iepriekšējā soļa izrēķinātās neapmierinātības automātisku attiecināšanu uz nākamo soli.
Runātās valodas apstrādes uzdevumā veikti padziļināti pētījumi emociju atpazīšanai audiodatos. Izveidoti neironi tīklu modeļi, kas apmācīti ar projekta laikā marķēto datu kopu, gan datu kopu, kas ietver brīvi pieejamus datus citām valodām. Veikta modeļu sākotnējā novērtēšana. Izteiksmīgas runas sintēzei pētīts vairākrunātāju paplašinājums Generative-flow (Glow) runas sintezatoram. Veiktajos eksperimentos Glow modelis uzrādījis daudzsološus rezultātus pat neoptimālam apmācības korpusam – pēc nedēļas ilgas apmācības modelis spēja sintezēt izteiksmīgu runu, kas raksturīga dažādiem runātājiem, un necieta no uzmanības problēmām
Atskaites periodā pabeigta sākotnējā prototipa izstrāde. Prototipu veido sistēma interaktīvai dialogu modelēšanai, kurā ar Wizard of Oz metodi iespējams vākt dialogu paraugus, kurus izmanto dialoga nākamās darbības prognozēšanas modeļa trenēšanai. Sākotnējā prototipa darbības novērtēšanai ir izveidots sabiedriskā transporta uzziņu jomas dialogu korpuss, kurā iekļauti 206 dialogi. Veikta prototipa un tā komponentu novērtēšana.
Publicēts 21.12.2020.
Projekta īstenošanas 6. posmā turpināti pētījumi par dabiskās valodas sapratnes modelēšanu, zināšanu izguvi no daudzvalodu tekstiem un daudzvalodīgas piekļuves nodrošināšanu, cilvēka-datora saziņas emocionālajiem aspektiem un runātās valodas paralingvistisko parametru modelēšanu. Pabeigts pētījums apakšaktivitātē “Mašīntulkošana dabiskās valodas vaicājumiem“, uzsākts apakšaktivitātes pētījums “Starpvalodu zināšanu pārnese“.
Dabīgās valodas sapratnes modelēšanas uzdevumā veikti pētījumi par nodoma noteikšanu ar mērķi radīt modeli, kas ir noturīgs pret kļūdām lietotāja izteikumos. Scenārijos ar ierobežotu apmācības datu kopu sākotnējais nodoma noteikšanas modelis sasniedz attiecīgi 60%, 78% un 86% precizitāti, kamēr, izmantojot visus apmācības datus, tas sasniedz 90% precizitāti. Kā modeļa uzlabošanas metode, tiek pārbaudīta lietotāja ievada automātiska normalizēšana (kļūdu labošana) priekšapstrādes solī. Savukārt dabiskās valodas sapratnes uzdevumā izstrādāts algoritms un modelis vairākvārdu personvārdu formu ģenerēšanai.
Dialogu scenāriju mācīšanās no datiem uzdevumā turpināta metožu pilnveide nākamās darbības prognozēšanai, izmantojot neironu tīklu modeļu arhitektūru un apmācības datos iekļaujot ekstralingvistisku informāciju. Apmācībai tiek izmantota ar sākotnējo prototipu ģenerētā sabiedriskā transporta uzziņu dialogu kopa. Apmācības dati ietver lietotāja izteikumu vai virtuālā aģenta (VA) darbības identifikatoru, entitātes, kas iegūtas no lietotāja izteikuma, VA uzstādītos konteksta mainīgos un parametrus, kas raksturo lietotāja izteikuma emocionalitāti – valenci un aktivāciju skalā no 0,0 līdz 8,0.
Turpinot pētījumus par zināšanu identificēšanu un zināšanu bāzes izveidi, izstrādāta metode nosaukto entitāšu normalizācijai, kas ļauj sasaistīt tās ar zināšanu bāzi, kas izmanto nosaukto entitāšu pamatformas.
Daudzvalodīgas piekļuves uzdevumā pabeigts pētījums par mašīntulkošanas lietojamību dabiskās valodas vaicājumos. Tika pētīti risinājumi un izstrādātas metodes trīs aktuālām pētniecības problēmām:
(1) pret kļūdām robustas neironu mašīntulkošanas (NMT) sistēmas, kas var apstrādāt negramatiskas ievades, izveide - pētījumā tika izstrādāta metode, kā radīt pret pareizrakstības un gramatikas kļūdām noturīgas NMT sistēmas, ļaujot nodrošināt 50% tulkojuma konsekvences uzlabojumu, salīdzinot ar bāzlīnijas NMT sistēmām, kas apmācītas ar “tīriem” datiem.
(2) NMT pielāgošanai jomai tika analizētas vairākas metodes - vienreizēja un dubulta attulkošana, retu/nejaušu un avotvalodas jomai piesaistītu datu atlase atpakaļtulkošanai, u.c.
(3) Lai uzlabotu teksta saskaņotību dokumenta tulkošanas laikā, tika pētīta dzimumu neobjektivitātes problēma NMT. Pētījumā tika piedāvāts nodalīt uzdevumu par gramatiskās dzimtes noteikšanu no uzdevuma iemācīties pareizi tulkot, ja šāda informācija ir pieejama. Pētījuma eksperimenti ar pieciem valodu pāriem parādīja, ka izstrādātā metode ļauj uzlabot precizitāti WinoMT testa datos (testa kopa, kura mērķis ir novērtēt dzimumu neobjektivitāti) līdz pat 25,8%.
Lietotāja emocionālā stāvokļa noteikšanas uzdevumā turpināta detalizēta dialogu anotēšana, izveidojot 11 sinhronus slāņus. Šajos slāņos aprakstītas un anotētas lingvistiskas, paralingvistiskas vienības, kurām varētu būt afektīva nozīme. Valodu vienības tiek anotētas slāņos, izmantojot cirkulāro afekta modeli (xy asis, Russell & Barrett, 1999), izmantojot emociju vārdus (izmantojot latviešu tezauru), kā arī paralingvistiskās vienības (runas izmaiņas, smiekli, elpošanas izmaiņas utt.). Sākotnējā datu kvalitatīvā analīze ļauj secināt, ka novērotās afektīvās pazīmes ir ļoti daudzveidīgas un liek domāt par lielu afektīvo pazīmju repertuāru neviendabīgumu. Pretstatā iepriekš uzskatītajam, ka cilvēka runā (vai sejā vai citā psihē, uzvedības izpausmēs) ir homogēnas, universālas afektīvās pazīmes, var secināt, ka šāda vienota pazīmju sistēma vismaz telefonsarunās nav labi novērojama.
Lietotāja emocionālā stāvokļa modelēšanas uzdevumā veikti pētījumi un izstrādāts modelis dialoga emociju intensitātes izmaiņu modelēšanai. Pētījumā tika modelēts aktuālais neapmierinātības līmenis pēc lietotāja puses dialoga gājiena teksta. Pētījuma gaitā izdevās parādīt, ka iespējams efektīvi prognozēt aktuālo neapmierinātības līmeni.
Runātās valodas apstrādes uzdevumā turpināta pašuzraudzītu modeļu piemērotības izpēte runas neplūstošo daļu atpazīšanai. Izveidota jauna testa kopa ar 3000 izteikumiem. Šai datu kopai pašuzraudzītā pieeja nedaudz pārspēj bāzlīniju (74% F1 pret 72% F1). Izteiksmīgas runas sintēzei pētīta Tacotron-2 vairākrunātāju modifikācija. Neskatoties uz daudziem eksperimentiem ar dažādiem apmācības korpusa sadalījumiem, izveidotais Tacotron-2 modelis konverģēja vienā balsī, kā arī cieta no problēmām, kas saistītas ar nepareizu uzmanību. Tāpēc uzsākta alternatīva risinājuma - vairākrunātāju paplašinājuma Generative-flow (Glow) runas sintezatoram – izpēte.
Atskaites periodā turpināta sākotnējā prototipa izstrāde. Prototipā tiek veidota sistēma interaktīvai dialogu paraugu vākšanai, kurus var izmanto dialogsistēmas komponentu tālākai apmācībai. Prototipa darbības novērtēšanai tiek veidots sabiedriskā transporta uzziņu jomas dialogu korpuss.
Publicēts 30.09.2020.
Projekta īstenošanas 5. posmā turpināti pētījumi par dabiskās valodas sapratnes modelēšanu, zināšanu izguvi no daudzvalodu tekstiem un daudzvalodīgas piekļuves nodrošināšanu, cilvēka-datora saziņas emocionālajiem aspektiem un runātās valodas paralingvistisko parametru modelēšanu. Uzsākts darbs pie sākotnējā multilingvālā virtuālā aģenta prototipa.
Turpināta lielu priekšapmācītu valodas modeļu (BERT, ALBERT un ELECTRA) izveide un novērtēšana latviešu valodai un šo modeļu apmācībai nepieciešamo datu sagatavošana. Veikta dažādo pētījumā izveidoto modeļu piemērotības novērtēšana atbildes atrašanas uzdevumā, izmantojot latviskotu SquAD datu kopu. Pētījuma rezultāti parādījuši, ka projekta mērķiem piemērotākais ir latviešu valodas BERT modelis, kurš SQuAD2.0 uzdevumā sasniedz F1 mēra vērtību 0.6.
Lai risinātu zināšanu identificēšanas uzdevumu nestrukturētā tekstā, veikta nosaukto entitāšu atpazīšanas (NER) metožu padziļināta izpēte - apzinātas datu kopas latviešu valodas NER risinājuma apmācībai un novērtēšanai, izveidoti un novērtēti vairāki NER modeļi, izmantojot priekšapmācītos BERT modeļus. Šī pētījumā labākie latviešu valodas nosaukto entitāšu atpazīšanas modeļi sasniedz 83 - 84% pēc F1 mēra.
Dialoga modelēšanas uzdevumā pētītas nākamās darbības prognozēšanas metodes, izmantojot rekurento LSTM tīklu ar priekšlaicīgas apmācības pārtraukšanu. Tā kā pirmie iegūtie rezultāti nav viennozīmīgi interpretējami, tiek pētīti šim uzdevumam piemērotākie neironu tīkla parametri un arhitektūras.
Zināšanu izvilkšanas, saglabāšanas un vaicājumu modelēšanas uzdevumiem turpināta literatūras apkopošana un analīze. Izstrādāti kritēriji novērtēšanas kopu izveidei. Apkopota informācija par zināmākajām novērtēšanas kopām un vairākas datu kopas salīdzinātas pēc izvirzītajiem kritērijiem.
Lietotāja emocionālā stāvokļa noteikšanai izstrādāts darbplūsmas modelis daudzslāņu anotēšanai, kurš paredzēts afektīvo parametru, afektīvo emocijvārdu un paralingvistisko pazīmju marķēšanai. Veikts pilotpētījums, kura laikā izvērtēti anotēšanas rīki (ELAN 5.8., DARMA un Annotation Pro) un aprobēts darbplūsmas modelis. Secināt, ka pētījuma vajadzībām vislabāk atbilst rīki Annotation Pro (izmantojams anotēšanai) un ELAN (izmantojams konvertēšanai). Izpētīti dialogu struktūru modeļi zvanu centru kontekstā. Paralēli veikti divi pilotpētījumi, nosakot spontānas runas laikā novērojamo balss skaļuma, intensitātes parametru saistību ar verbālā satura afektīvajām pazīmēm.
Turpināti pētījumi par cilvēka datora komunikācijas adaptāciju lietotāja emocionālajam stāvoklim – veikta pieejamo ar emocijām anotēto dialogu datu kopu analīze, emociju analīzes metožu un rīku izpēte, dialoga emociju intensitātes izmaiņu konceptuālā modeļa izstrāde un klientu atbalsta dialogu tekstu sagatavošana prognozēšanas modeļa veidošanai. Pieejamo ar emocijām anotēto dialogu datu avotu pārskatam tika veikta dažādu teksta datu kopu analīze pēc vairākiem kritērijiem, šī pētījuma rezultāti apkopoti zinātniskā publikācijā “Leonova V. Review of Non-English Corpora Annotated for Emotion Classification in Text”, kas pieņemta konferencei Baltic DB&IS 2020. Uzsākts padziļināts pētījums neapmierinātības intensitātes prognozēšanai klientu atbalsta dialogu tekstos, analizējot frustrāciju (neapmierinātību) un tās intensitāti katrā klienta izteikumā.
Runātās valodas apstrādes uzdevumā padziļināti pētīti runātāja atpazīšanas, runas ierakstu segmentācijas (diarizācija) un runas neplūstošo daļu atpazīšanas un filtrēšanas uzdevumi. Runātāja atpazīšanas uzdevumā vislabākos rezultātus sasniedza x-vector modelis, kas apmācīts ar angļu valodas datiem, bet pielāgots ar latviešu valodas runas korpusu. Novērtējot audiosegmentācijas uzdevumā Kaldi x-vector diarisation un LIUM SpkDiarizatio, iegūts DER novērtējums 14.25% pielāgotam x-vector modelim un 30.45% LIUM SpkDiariz bāzlīnijai. Runas neplūstošo daļu atpazīšanas uzdevumā tika pētīta pašuzraugoša
(self-supervised) pieeja. Ar šo metodi izdevās pārspēt bāzlīniju (63% F1 pret 54% F1), tomēr modelis ir pārāk neprecīzs, lai to izmantotu praksē.
Izteiksmīgas runas sintēzes uzdevumā pētītas metodes, kas iemācās runas izteiksmes variācijas nepārraudzītā veidā no runātās valodas korpusa. Paralēli tiek pētītas metodes (piem., ne-autoregresīvās sintēzes metodes un ātrākas mel-spektrogramu pārveides metodes) runas sintēzes kvalitātes un sintēzes ātruma uzlabošanai, lai kvalitatīvu runas sintēzi varētu izmantot reālā laika dialogos
Publicēts 18.06.2020.
Projekta īstenošanas 4. posmā turpināti pētījumi par dabiskās valodas sapratnes modelēšanu, zināšanu izguvi no daudzvalodu tekstiem, daudzvalodīgas piekļuves nodrošināšanu, cilvēka-datora saziņas emocionālajiem aspektiem un runātās valodas paralingvistisko parametru modelēšanu.
Dabiskās valodas sapratnes uzdevuma pētījumi pārskata periodā saistīti ar BERT un ALBERT modeļu izveidi latviešu valodai un šo modeļu apmācībai nepieciešamo datu sagatavošanu. Turpināta dažādo modeļu piemērotības novērtēšana atbildes atrašanas uzdevumā, izmantojot latviskotu SquAD datu kopu.
Pārskata periodā turpināti pētījumi par zināšanu izvilkšanu no tekstiem. Uzsākta nosaukto entitāšu atpazīšanas (NER) uzdevuma padziļināta izpēte un novērtēšana, izmantojot sagatavotos BERT modeļus. Apzinātas datu kopas latviešu valodai NER risinājuma apmācībai un novērtēšanai. Turpināta zinātniskās literatūras analīze par metodēm automātiskai zināšanu izvilkšanai, īpaši pētot hibrīdās vairāku “sprieduma lēcienu” jautājumu atbildēšanas metodes (hybrid multi-hop QA).
Dabiskās valodas izteikumu automātiskas tulkošanas uzdevumā turpināti pētījumi par mašīntulkošanas sistēmas pielāgošanu negramatisku datu (runas atpazīšanas sistēmas izvada, tērzēšanas valodas u.c.) tulkošanai.
Lietotāja emocionālā stāvokļa noteikšanai un modelēšanai turpināta afekta tezaura izveide un afekta pazīmju kategorizācijas sistēmas izveide. Uzsākta afekta anotēšana audioierakstos, aprobējot izvēlēto kategorizācijas sistēmu un novērtējot mūsdienīgākos anotēšanas rīkus.
Pārskata periodā turpināti pētījumi par cilvēka datora komunikācijas adaptāciju lietotāja emocionālajam stāvoklim. Turpināta datu kopu dialogu modelēšanai apzināšana un izpēte, uzsāks pētījums par empātiskas dialogsistēmas izveidi. Uzsākta dialoga emociju automātiskas analīzes pieejas izstrāde pēc izvēlēto emociju intensitātes.
Turpināti pētījumi par labākajām metodēm izteiksmīgas runas sintēzei un emocionālas runas atpazīšanai datu nepietiekamības apstākļos. Turpināta novērtēšana audiosegmentācijas uzdevumam, salīdzinot Kaldi x-vector diarisation un LIUM SpkDiarization. Sagatavoti nepieciešamie dati atbilstoši DIHARD challenge ieteikumiem. Iegūts novērtējums pēc DER (Diarization error rate): LIUM: 67.55, bet Xvector: 60.80.
Publicēts 31.03.2020.
Pārskata periodā turpināti pētījumi par efektīvākajām metodēm pašapmācošu virtuālo sarunu biedru izveidei. Veikta modeļu un metožu analīze dialoga stāvokļa izsekošanas un nākamās darbības prognozēšanas uzdevumiem. Veikta dažādu pētījumam nepieciešamo BERT modeļu izveide un analīze latviešu valodai, veikta bāzlīnijas novērtēšana SquAD uzdevumā latviešu valodā.
Uzsākti pētījumi par zināšanu izvilkšanu no tekstiem. Veikta sākotnējā analīze diviem risinājumiem – komponentēs balstītai zināšanu izguvei (pārskata periodā koncentrējoties uz nosauktajām entitātēm) un pašapmācošamies un pašpapildinošamies modeļiem, analizējot pašreiz labākos rezultātus angļu valodai un pētot to adaptēšanas iespējas.
Dabiskās valodas izteikumu automātiskai tulkošanai uzsākti eksperimenti mašīntulkošanas sistēmas pielāgošanai darbam ar runas atpazīšanas sistēmas izvadu. Mašīntulkošanas sistēmās izmantota “transformer” tipa tīkla arhitektūra, tās apmācītas ar WMT 2017 datu kopu, papildinot to ar mākslīgi sintezētu un atpazītu runāto tekstu avotvalodā un to tulkošanas ekvivalentiem mērķvalodā. Sākotnējie eksperimentu rezultāti ļauj secināt, ka jaukto datu sistēma veiksmīgi pielāgojas darbam ar runas atpazīšanas sistēmas izvadu.
Lietotāja emocionālā stāvokļa noteikšanai un modelēšanai uzsākts pilotpētījums par multimodālu dialogu modelēšanu un anotēšanu. Veikta audiālu dialoga fragmentu analīze, esošo tehnisko palīglīdzekļu novērtēšana. Veikta datu apstrāde, iegūstot transkribētā teksta kvalitātes rādītājus un emociju vārdu parametrus. Sagatavoti scenāriji uzlaboto dialogu struktūru veidošanai. Apzinātas datu kopas dialogu modelēšanai, un izstrādāta saskarne dialoga datu manuālai tulkošanai.
Turpināti pētījumi par labākajām metodēm izteiksmīgas runas sintēzei un emocionālas runas atpazīšanai datu nepietiekamības apstākļos. Uzsākta novērtēšana audio segmentācijas uzdevumam.
Publicēts 31.12.2019.
Projekta īstenošanas 2. posmā (no 2019. gada 1. jūlija līdz 2019. gada 30. septembrim) turpinājās darbs pie vairākām projekta Rūpnieciskās pētniecības aktivitātēm:
1.1. Dabiskās valodas saprašana
1.2. Dabiskās valodas ģenerēšana
1.3. Dialoga scenāriju mācīšanās no datiem
2.1. Zināšanu identificēšana tekstu datos
2.2. Automātiska daudzvalodu zināšanu bāzes izveide
3.1. Mašīntulkošana dabiskās valodas vaicājumiem
5.1. Paralingvistisko pazīmju atpazīšana un runātās valodas apstrāde dialogos
5.2. Izteiksmīgas runas sintēze dialogiem
Pārskata posmā tika turpināts darbs atbilstoši sagatavotajam pētījuma plānam, izvērsts darbs pie galvenajiem problēmjautājumiem, un turpinājās pētījumam nepieciešamo datu kopu sagatavošana.
Publicēts 30.09.2019.
Projekta īstenošanas 1. posmā (no 2019. gada 1. aprīļa līdz 2019. gada 30. jūniju) notika darbs pie vairākām projekta Rūpnieciskās pētniecības aktivitātēm:
1.1. Dabiskās valodas saprašana
1.2. Dabiskās valodas ģenerēšana
1.3. Dialoga scenāriju mācīšanās no datiem
2.1. Zināšanu identificēšana tekstu datos
2.2. Automātiska daudzvalodu zināšanu bāzes izveide
3.1. Mašīntulkošana dabiskās valodas vaicājumiem
5.1. Paralingvistisko pazīmju atpazīšana un runātās valodas apstrāde dialogos
5.2. Izteiksmīgas runas sintēze dialogiem
Pārskata posmā tika sagatavots pētījuma plāns, apzināti galvenie problēmjautājumi, un uzsākta pētījumam nepieciešamo datu kopu un jaunāko literatūras avotu apkopošana un analīze.
Publicēts 30.06.2019.